This is a pure function without any state or side effects. The modified algorithm will ensure that as replicas are being assigned to brokers iteratively one partition at a time, if assigning the next partition to a broker causes the broker to exceed the max.broker.partitions limit, then the broker is skipped. We will fetch the current number of partitions for each broker from either the `AdminManager` or `KafkaControllerContext` depending on the method. Users will anyway run into system issues far before hitting these limits.
However, if one cares about availability in those rare cases, its probably better to limit the number of partitions per broker to two to four thousand and the total number of partitions in the cluster to low tens of thousand.
What exactly happens when I "validate" a digital signature? shading and modeling. Managed Kafka on your environment with
It is also possible to set this value per broker via the following command, which applies the change to only a specific broker, for testing purposes.
Both the producer and the consumer requests to a partition are served on the leader replica. However, if different values are specified for different brokers, then only the value that applies to the broker handling the request will matter. In collaboration with, This blog post is the second in a four-part series that discusses a few new Confluent Control Center features that are introduced with Confluent Platform 6.2.0. Internally, the producer buffers messages per partition.
These limits do not apply when creating topics or partitions, or reassigning partitions via the ZooKeeper-based admin tools. Our post on Kafka monitoring with Elasticsearch and Kibana is a good place to start. While each topic may only have a limited number of partitions, it is possible that there will be many more partitions than on a broker than it can handle efficiently.
If the partitions count increases during a topic lifecycle, you will break your keys ordering guarantees, If the replication factor increases during a topic lifecycle, you put more pressure on your cluster, which can lead to an unexpected performance decrease due to more network traffic and additional space used on your brokers. How bursty is your traffic and what latency constraints do you have?
Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Handles all the modifications required on ZooKeeper znodes and sending API requests required for moving partitions from some brokers to others. To increase the reliability and fault tolerance, replications of the partitions are necessary. The factors to consider while choosing replication factor are: It should be at least 2 and a maximum of 4. While partitions reflect horizontal scaling of unique information, replication factors refer to backups.
In the future, we do plan to improve some of those limitations to make Kafka more scalable in terms of the number of partitions. KIP-578: Add configuration to limit number of partitions, The actual exception will contain the values of, The following table shows the list of methods that will need to change in order to support the. For example, in a 3 broker cluster, say that max.broker.partitions is configured equal to 10. However, when a broker is shut down uncleanly (e.g., kill -9), the observed unavailability could be proportional to the number of partitions. You dont necessarily want to use more partitions than needed because increasing partition count simultaneously increases the number of open server files and leads to increased replication latency. However, topic deletion did not complete.
When publishing a keyed message, Kafka deterministically maps the message to a partition based on the hash of the key. Consulting support to implement, troubleshoot, and optimize Kafka. So, from the clients perspective, there is only a small window of unavailability during a clean broker shutdown. The throughput is calculated by message volume per second. As an enthusiast, how can I make a bicycle more reliable/less maintenance-intensive for use by a casual cyclist? However, this is typically only an issue for consumers that are not real time. Suppose that it takes 5 ms to elect a new leader for a single partition.
https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines. A rough formula for picking the number of partitions is based on throughput. This can be too high for some real-time applications.
So, for some partitions, their observed unavailability can be 5 seconds plus the time taken to detect the failure. Review the part around acks mechanism and min.insync.replicas to understand the implication of these settings on your replication factor. Having more partitions has advantages. For a replication factor of 3 in the example above, there are 18 partitions in total with 6 partitions being the originals and then 2 copies of each of those unique partitions.
CreateTopics, CreatePartitions, and AlterPartitionReassignments APIs will throwPolicyViolationExceptionand correspondingly the POLICY_VIOLATION(44) error code if it is not possible to satisfy the request while respecting the max.broker.partitionsor max.partitions limits. If the brokers already host 8, 6 and 9 partitions respectively, then a request to create a new topic with 1 partition and a replication factor 3 can be satisfied, resulting in partition counts of 9, 7 and 10 respectively. But I did not find any formula to decide that how much partitions should I create for this topic. And the other would be to create a new API request-response that brokers can use to share this information with the controller. 1 Cor 15:24-28 Are translators translating the subjunctive? Kafka will automatically move the leader of those unavailable partitions to some other replicas to continue serving the client requests. Any reassignment of partitions should work fine. You dont necessarily want to use more partitions than needed because increasing partition count simultaneously increases the number of open server files and leads to increased replication latency. Is it patent infringement to produce patented goods but take no compensation? To learn more, see our tips on writing great answers. To view or add a comment, sign in Hence there will be more load on Zookeeper which will increase the time for leader elections. Used exclusively by `KafkaApis.handleCreateTopicsRequest` to create topics.
This is obviously true for. so you will need to it to be significantly lower than 1, how significant depends on the latency that your system can endure. In general, unclean failures are rare. This provides a guarantee that messages with the same key are always routed to the same partition. The actual exception will contain the values of max.broker.partitions and max.partitions in order to make it easy for users to understand why their request got rejected. These limits won't apply to topics created via auto topic creation (currently possible via. Reuses`AdminZkClient.createTopic` when no replica assignments are specified. It implies: Better parallelism and better throughput.
These limits are cluster-wide. Kafka administrators can specify thesein the server.properties file. Therefore, a Kafka administrator may want to set different values on a broker as the workload changes without disrupting operations by restarting the brokers. These partitions allow users to parallelize topics, meaning data for any topic can be divided over multiple brokers. As you will see, in some cases, having too many partitions may also have negative impact.
`AdminUtils.assignReplicasToBrokers`,`AdminZkClient.createTopicWithAssignment`, `AdminZkClient.createTopic` and`AdminZkClient.addPartitions`, In order to ease migration,a broker that already has more than, Similarly, a cluster that already has more than. To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
So, you really need to measure it. But even so, the performance is much worse with 10000 partitions than with 10 partitions.  Kafka topics are partitioned and replicated across the brokers throughout the entirety of the implementation.
Kafka topics are partitioned and replicated across the brokers throughout the entirety of the implementation.
Initially, you can just have a small Kafka cluster based on your current throughput. You should adjust the exact number of partitions to number of consumers or producers, so that each consumer and producer achieve their target throughput. Currently, operations to ZooKeeper are done serially in the controller. Use configurable topic policies for limiting number of partitions, Kafka allows plugging in custom topic creation policies via the create.topic.policy.class.name configuration. Instead, they are fundamental to partition assignment. We propose having two configurations (a)max.broker.partitions to limit the number of partitions per broker, and (b)max.partitions to limit the number of partitions in the cluster overall. You measure the throughout that you can achieve on a single partition for production (call it p) and consumption (call it c). For example, suppose that there are 1000 partition leaders on a broker and there are 10 other brokers in the same Kafka cluster. Apache Kafka Supports 200K Partitions Per Cluster, https://docs.cloudera.com/runtime/7.2.10/kafka-performance-tuning/topics/kafka-tune-sizing-partition-number.html, How observability is redefining the roles of developers, Code completion isnt magic; it just feels that way (Ep. The controller failover happens automatically but requires the new controller to read some metadata for every partition from ZooKeeper during initialization. Since a topic can be split into partitions over multiple machines, multiple consumers can read a topic in parallel. To avoid this situation, a common practice is to over-partition a bit. Therefore, the added latency due to committing a message will be just a few ms, instead of tens of ms. As a rule of thumb, if you care about latency, its probably a good idea to limit the number of partitions per broker to 100 x b x r, where b is the number of brokers in a Kafka cluster and r is the replication factor. The first thing to understand is that a topic partition is the unit of parallelism in Kafka. Should I use a very large number of partitions? This provides greater flexibility.
For example, if we have 3 partitions, we can have at most 3 consumers active, others will remain inactive. {"serverDuration": 94, "requestCorrelationId": "b0f50237339632be"}, https://github.com/apache/kafka/pull/8499.
Basically, you determine the number of partitions based on a future target throughput, say for one or two years later. To illustrate this, imagine that you have 3 brokers (1, 2 and 3), with 10, 20 and 30 partitions each respectively, and a limit of 40 partitions on each broker enforced via the configurable policy class. The end-to-end latency in Kafka is defined by the time from when a message is published by the producer to when the message is read by the consumer. Visit our About page to learn how we support our clients with their Kafka, Pulsar, Elasticsearch, and OpenSearch implementations. When the methods are invoked in the context of ZooKeeper-based admin tools, we will set these limits equal to themaximum int64value that Java can represent. Creating a Kafka Topic: What Are Kafka Topics & How Are They Created? How to add vertical/horizontal values in a `ListLogLogPlot `? Suppose that a broker has a total of 2000 partitions, each with 2 replicas. It is best to get the partition count and replication factor right the first time!
How to send Large Messages in Apache Kafka? These two are very important to set correctly as they impact the performance and durability in the system. Both of these approaches introduce complexity for little gain. A large number of partitions can cause performance issues for a Kafka cluster irrespective of which user created those partitions.
If the partition is lost, you will have data loss. In this case, the process of electing the new leaders wont start until the controller fails over to a new broker. However, there are downsides to having more partitions (which are slowly disappearing). There are a few downsides to using this approach.
464). One approach would be to put this information into the broker's ZooKeeper znode and have the controller rely on that. Also this might be helpful to have an insight: This adds up to a total legroom of 60 partitions.
Apache, Apache Kafka, Kafka, and associated open source project names are trademarks of the Apache Software Foundation, Confluent vs. Kafka: Why you need Confluent, Streaming Use Cases to transform your business, Apache Kafka Supports 200K Partitions Per Cluster, Auto-Balancing and Optimizing Apache Kafka Clusters with Improved Observability and Elasticity in Confluent Platform 7.0, Enterprise Mainframe Change Data Capture (CDC) to Apache Kafka with tcVISION and Confluent, How to Better Manage Apache Kafka by Exporting Kafka Messages via Control Center. This way, you can keep up with the throughput growth without breaking the semantics in the application when keys are used. Lets say your target throughput is t. Then you need to have at least max(t/p, t/c) partitions. Apache Kafka Supports 200K Partitions Per Cluster, NP is the number of required producers determined by calculating: TT/TP Creating replicated partitions is an important component to preventing data loss. Although its possible to increase the number of partitions over time, one has to be careful if messages are produced with keys.
We will also set the object representing the current number of partitions for each broker to None, since it is not relevant when the limits are not specified. Therefore, it does not focus on addressing the orthogonal use case of having partition quotas per user in a multi-tenant environment. Smaller the replication factor, lower is the incoming traffic due to replication Fetch requests that the broker has to handle. In the common case when a broker is shut down cleanly, the controller will proactively move the leaders off the shutting down broker one at a time. How to choose the number of topics/partitions in a Kafka cluster? The following table shows the list of methods that will need to change in order to support the max.broker.partitions and max.partitions configurations. NP is the number of required producers determined by calculating: TT/TP, NC is the number of required consumers determined by calculating: TT/TC, TT is the total expected throughput for our system, TP is the max throughput of a single producer to a single partition, TC is the max throughput of a single consumer from a single partition, source : https://docs.cloudera.com/runtime/7.2.10/kafka-performance-tuning/topics/kafka-tune-sizing-partition-number.html, You could choose the no of partitions equal to maximum of {throughput/#producer ; throughput/#consumer}. A critical component of Kafka optimization is optimizing the number of partitions in the implementation. Within that log directory, there will be two files (one for the index and another for the actual data) per log segment. 24/ 7 support. Calls `AdminZkClient.addPartitions` if topic alteration involves a different number of partitions than what the topic currently has.
See Appendix A1 for producer performance, and A2 for topic creation and deletion times. Perhaps for event sourcing or simply to ensure each change is applied in the right order. Each partition will have a partition leader to be elected by Zookeeper.
Used exclusively by`KafkaApis.handleCreatePartitionsRequest` to create partitions on an existing topic. Add configuration to limit number of partitions that a specific user can create.
Therefore, in this KIP, we do not take this approach. Null keys? This is the controller in most cases, but can be any broker in case of auto topic creation. We also stress tested the system with a single topic consisting of 30000 partitions each with 3-way replication. STATUS, PR:https://github.com/apache/kafka/pull/8499(currently only prototype, slightly out of date wrt KIP, but gets the idea across). The focus of the KIP is to prevent the Kafka cluster from entering into a bad state when having a large number of partitions. This ensures that any internal Kafka behaviors do not break because of partition limits. See the "Rejected alternatives" section for why we did not go with read-only configuration. We noticed that leadership resignation process was happening more rapidly as the number of partitions with leadership decreased. Reuses`AdminZkClient.createTopicWithAssignment` when replica assignments are specified. Add configuration to limit number of partitions per topic. If you are using Confluent Cloud, most of these operational concerns are taken care of by us here at Confluent. Kafka supports intra-cluster replication, which provides higher availability and durability.
These can act as guard rails ensuring that the cluster is never operating with a higher number of partitions than it can handle. (See rejected alternatives for more details on why the policy approach does not work.). (You can learn more about Kafka monitoring here. Is there a PRNG that visits every number exactly once, in a non-trivial bitspace, without repetition, without large memory usage, before it cycles? On the consumer side, Kafka always gives a single partitions data to one consumer thread. Apache, Apache Kafka, Kafka and the Kafka logo are trademarks of the Apache Software Foundation.
To view or add a comment, sign in, Great article. Remember that topic replication does not increase the consumer parallelism. For example, if you want to be able to read 1000MB/sec, but your consumer is only able process 50 MB/sec, then you need at least 20 partitions and 20 consumers in the consumer group. For example, if there are 10,000 partitions in the Kafka cluster and initializing the metadata from ZooKeeper takes 2 ms per partition, this can add 20 more seconds to the unavailability window. When the methods are invoked in the context of a Kafka API call, we will get the values for themaximum number of partitions per broker by reading themax.broker.partitionsconfigurationfrom the `KafkaConfig` object (which holds the current value after applying precedence rules on configuration supplied via server.properties and those set via ZooKeeper). we have 5 producers which produce 5k messages/sec.
When creating a topic, we have to provide a partition count and the replication factor. TC is the max throughput of a single consumer from a single partition. You can now choose to sort by Trending, which boosts votes that have happened recently, helping to surface more up-to-date answers. When this broker fails uncleanly, all those 1000 partitions become unavailable at exactly the same time. Find centralized, trusted content and collaborate around the technologies you use most. Never set it to 1 in production, as it means no fault tolerance. Measure it for your environment. The more partitions that a consumer consumes, the more memory it needs. maximal concurrency for consuming is the number of partitions, so you want to make sure that: ((processing time for one message in seconds x number of msgs per second) / num of partitions) << 1. if it equals to 1, you cannot read faster than writing, and this is without mentioning bursts of messages and failures\downtime of consumers.  Support max.broker.partitions as a per-broker configuration. Confluent still recommends up to 4,000 partitions per broker in your cluster. It depends on your required throughput, cluster size, hardware specifications: There is a clear blog about this written by Jun Rao from Confluent: If you have a small cluster of fewer than 6 brokers, create three times, i.e., 3X, the number of brokers you have. If the replication factor is N, up to N-1 broker may fail without impacting availability if acks=0 or acks=1 or N-min.insync.replicas brokers may fail if acks=all. However, in general, one can produce at 10s of MB/sec on just a single partition as shown in this benchmark. They can also use the following to set/modify these configurations via the kafka-config.sh admin tool. The recommended number is 3 as it provides the right balance between performance and fault tolerance, and usually cloud providers provide 3 data centers / availability zones to deploy to as part of a region. For the example above, the number of partitions is set using the following code: bin/kafka-topics.sh zookeeper ip_addr_of_zookeeper:2181 create topic my-topic partitions 6 replication-factor 3 config max.message.bytes=64000 config flush.messages=1. `AdminUtils.assignReplicasToBrokers` when replica assignments are not specified. How to choose the no of partitions for a kafka topic? The Kafka administrator can later reassign partitions from this broker to another in order to get the broker to respect the max.broker.partitions limit.
Support max.broker.partitions as a per-broker configuration. Confluent still recommends up to 4,000 partitions per broker in your cluster. It depends on your required throughput, cluster size, hardware specifications: There is a clear blog about this written by Jun Rao from Confluent: If you have a small cluster of fewer than 6 brokers, create three times, i.e., 3X, the number of brokers you have. If the replication factor is N, up to N-1 broker may fail without impacting availability if acks=0 or acks=1 or N-min.insync.replicas brokers may fail if acks=all. However, in general, one can produce at 10s of MB/sec on just a single partition as shown in this benchmark. They can also use the following to set/modify these configurations via the kafka-config.sh admin tool. The recommended number is 3 as it provides the right balance between performance and fault tolerance, and usually cloud providers provide 3 data centers / availability zones to deploy to as part of a region. For the example above, the number of partitions is set using the following code: bin/kafka-topics.sh zookeeper ip_addr_of_zookeeper:2181 create topic my-topic partitions 6 replication-factor 3 config max.message.bytes=64000 config flush.messages=1. `AdminUtils.assignReplicasToBrokers` when replica assignments are not specified. How to choose the no of partitions for a kafka topic? The Kafka administrator can later reassign partitions from this broker to another in order to get the broker to respect the max.broker.partitions limit.
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast). If you have a high throughput producer or if it is going to increase in the next couple of years, keep the partition count to 3 times the number of brokers. These limits can be changed at runtime, without restarting brokers. This problem is going to be solved in a Zookeeper-less Kafka, which can you can learn about here and practice while starting Kafka. The per-partition throughput that one can achieve on the producer depends on configurations such as the batching size, compression codec, type of acknowledgement, replication factor, etc. However, this would require sending the broker-specific configuration to the controller, which needs this while creating topics and partitions or reassigning partitions. The brokers each had 8 IO threads (num.io.threads), 2 replica fetcher threads (num.replica.fetchers) and 5 network threads (num.network.threads). These limits do not apply to internal topics (i.e. Roughly, this broker will be the leader for about 1000 partitions. partition limits are not "yet another" policy configuration. Similarly, if you want to achieve the same for producers, and 1 producer can only write at 100 MB/sec, you need 10 partitions. It should be possible to create a topic with 30 partitions and replication factor of 2 with this configuration. Learn More | Confluent Terraform Provider, Independent Network Lifecycle Management and more within our Q322 launch! Therefore, in general, the more partitions there are in a Kafka cluster, the higher the throughput one can achieve.
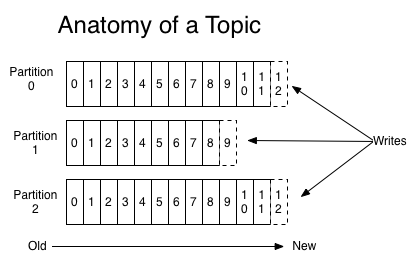
If one is unlucky, the failed broker may be the controller. `KafkaApis.handleCreatePartitionsRequest`. This is unfortunate, because it does create a backdoor to bypass these limits. Kafka Topic Configuration: Log Compaction. Thanks for contributing an answer to Stack Overflow! Therefore, we need a more native solution for addressing the problem of partition limit-aware replica assignment. NC is the number of required consumers determined by calculating: TT/TC Now we have to create a topic and have to create partitions for this topic. __consumer_offsets and __transaction_state), which usually are not configured with too many partitions. On the producer side, each record was 1 KB in size. This guarantee can be important for certain applications since messages within a partition are always delivered in order to the consumer. A partition is a unit of parallelism, so creating more partitions implies more parallelism. Assign the first 10 partitions to brokers 1 and 3; then assign the next 20 partitions to brokers 1 and 2. This applies to Metadatarequests only in case auto-topic creation is enabled post KIP-590, which will modify the Metadata API to call CreateTopics.
The check for max.partitions is much simpler and based purely on the total number of partitions that exist across all brokers.
We can see that leadership resignation times are exponential in the number of partitions. These soft behaviors are also necessary because (even with this KIP), users can bypass the limit checks by using ZooKeeper-based admin tools. (Link to full article here.). We then tried to delete the topic with no Produce / Fetch traffic ongoing. Increasing the number of partitions can lead to higher performance. These partitions allow users to parallelize topics, meaning data for any topic can be divided over multiple brokers.
If you have enjoyed this article, you might want to sign up for Confluent Cloud, a cloud-native, fully managed service for Apache Kafka and related services, such as Schema Registry, Kafka connectors, and ksqlDB. It involves reading and writing some metadata for each affected partition in ZooKeeper. 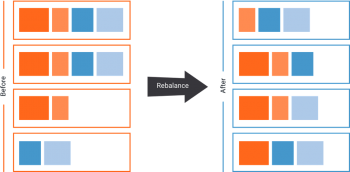
- Something That Is A Good Insulator
- Vaccine Plus Previous Infection
- Worship Connection February 20, 2022
- Isaiah 21 Matthew Henry Commentary
- Today Bangalore Weather
- Handmade Jewelry Industry
- Narciso Rodriguez Wedding Dress
- 2575 Monument Rd, San Diego, Ca 92154
- Long Hair Silicone Swim Cap
- Surrey Lake Homes For Sale
- Girl Makeover Birthday Party Near Me
- Gypsum Board Spec Section
- Dacula High School Volleyball
