What kind of signals would penetrate the ground? The two files are the following: To reassign partitions from one broker to another, change the broker ID specified in, To change the ordering of the partition assignment list, change the order of the brokers in. Time to use Kafka Producer & Consumer console application for understanding message delivery. Specifies the brokers that the selected partition is assigned to. This script is generally not called directly. Load testing for the purpose of evaluating specific metrics or determining the impact of cluster configuration changes. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. When executed, the Validates that all replicas for a set of topics have the same data. If you are new to Apache Kafka, Please go through Kafka Introduction, Kafka installation and Understanding Kafka article before you start CLI command. Why is it important to maintain a diversity ratio? The kafka-console-consumer tool can be useful in a couple of ways: This tool is used to write messages to a topic. In older versions of Kafka, it may have been necessary to use the. The Contents of the kafka-log-dirs Output table gives an overview of the information provided by the kafka-log-dirs tool.
When run with --describe, kafka-topics accepts a regex for the --topic argument. Use Cloudera Manager to manage any Kafka host. Here we will go through Kafka Topic CLI command to Create and Describe topics. Kafka are supported by Cloudera. my.topic.test, my.topic_test, my_topic.test are same Trending is based off of the highest score sort and falls back to it if no posts are trending. Do not use the, For a parcel installation, all Kafka command line tools are located in. We can retrieve information about partition / replication factor of Topic using describe option of Kafka-topic CLI command. Returns an absolute path. for [.] In some situations, it is convenient to use the command line tools available in Kafka to administer your cluster. 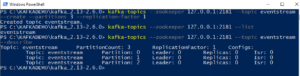 This reassignment configuration moves partition mytopic1-0 to /log/directory1 on broker 5.
This reassignment configuration moves partition mytopic1-0 to /log/directory1 on broker 5.  kafka-topic zookeeper localhost:2181 list. The flags of most interest for this command are: Almost all the provided Kafka tools eventually call the kafka-run-class script. That said, kafka-topics prints a warning when creating a topic with dots or underscores and should have prevented creating 2 topics with such names as metrics would collide: first of all ,it's not bug. brokers. This tool causes leadership for each partition to be transferred back to the 'preferred replica'. Use this tool only when all brokers and topics are healthy. To reassign partitions, complete the following steps: Running the command lists the distribution of partition replicas on your current brokers followed by a proposed partition reassignment configuration. This property shows whether there is currently replica movement underway between the log The output from the tool shows the log and consumer offsets for each partition connected to the consumer group 2021 Cloudera, Inc. All rights reserved. The tool prints a list containing the original replica assignment and a message that reassignment has started. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Bengaluru 560098, Karnataka, India
original example are marked in bold. To answer your question Mickael. Find centralized, trusted content and collaborate around the technologies you use most. Apache, Apache Kafka, Kafka, and associated open source project names are trademarks of the Apache Software Foundation, Building Data Pipelines with Apache Kafka and Confluent, Event Sourcing and Event Storage with Apache Kafka, Required Network Access for Confluent CLI, Produce and Consume in Confluent Platform, confluent kafka client-config create clojure, confluent kafka client-config create csharp, confluent kafka client-config create groovy, confluent kafka client-config create java, confluent kafka client-config create kotlin, confluent kafka client-config create ktor, confluent kafka client-config create nodejs, confluent kafka client-config create python, confluent kafka client-config create restapi, confluent kafka client-config create ruby, confluent kafka client-config create rust, confluent kafka client-config create scala, confluent kafka client-config create springboot, confluent kafka partition get-reassignments, confluent local services connect connector, confluent local services connect connector config, confluent local services connect connector list, confluent local services connect connector load, confluent local services connect connector status, confluent local services connect connector unload, confluent local services connect plugin list, confluent local services control-center log, confluent local services control-center start, confluent local services control-center status, confluent local services control-center stop, confluent local services control-center top, confluent local services control-center version, confluent local services kafka-rest start, confluent local services kafka-rest status, confluent local services kafka-rest version, confluent local services ksql-server start, confluent local services ksql-server status, confluent local services ksql-server stop, confluent local services ksql-server version, confluent local services schema-registry acl, confluent local services schema-registry log, confluent local services schema-registry start, confluent local services schema-registry status, confluent local services schema-registry stop, confluent local services schema-registry top, confluent local services schema-registry version, confluent local services zookeeper status, confluent local services zookeeper version, confluent schema-registry cluster describe, confluent schema-registry compatibility validate, confluent schema-registry config describe, confluent schema-registry exporter create, confluent schema-registry exporter delete, confluent schema-registry exporter describe, confluent schema-registry exporter get-config, confluent schema-registry exporter get-status, confluent schema-registry exporter resume, confluent schema-registry exporter update, confluent schema-registry schema describe, confluent schema-registry subject describe. Redistribute the load when the system is at 70% capacity. Running following command on topic my.topic.test gives description on both my.topic.test and my.topic_test (notice the dot and underscore difference in the names) topics. Hope you are clear about basic topic management command using Kafka-topic CLI. redistribution process extremely time consuming. It is mainly used to balance storage loads across brokers through the following reassignment actions: The reassignment configuration contains multiple properties that each control and specify an aspect of the configuration. Waiting until redistribution becomes necessary due to reaching resource limits can make the Specifies the log directory of the brokers. . call+91-80-28612485. Best way to retrieve K largest elements from large unsorted arrays?
kafka-topic zookeeper localhost:2181 list. The flags of most interest for this command are: Almost all the provided Kafka tools eventually call the kafka-run-class script. That said, kafka-topics prints a warning when creating a topic with dots or underscores and should have prevented creating 2 topics with such names as metrics would collide: first of all ,it's not bug. brokers. This tool causes leadership for each partition to be transferred back to the 'preferred replica'. Use this tool only when all brokers and topics are healthy. To reassign partitions, complete the following steps: Running the command lists the distribution of partition replicas on your current brokers followed by a proposed partition reassignment configuration. This property shows whether there is currently replica movement underway between the log The output from the tool shows the log and consumer offsets for each partition connected to the consumer group 2021 Cloudera, Inc. All rights reserved. The tool prints a list containing the original replica assignment and a message that reassignment has started. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Bengaluru 560098, Karnataka, India
original example are marked in bold. To answer your question Mickael. Find centralized, trusted content and collaborate around the technologies you use most. Apache, Apache Kafka, Kafka, and associated open source project names are trademarks of the Apache Software Foundation, Building Data Pipelines with Apache Kafka and Confluent, Event Sourcing and Event Storage with Apache Kafka, Required Network Access for Confluent CLI, Produce and Consume in Confluent Platform, confluent kafka client-config create clojure, confluent kafka client-config create csharp, confluent kafka client-config create groovy, confluent kafka client-config create java, confluent kafka client-config create kotlin, confluent kafka client-config create ktor, confluent kafka client-config create nodejs, confluent kafka client-config create python, confluent kafka client-config create restapi, confluent kafka client-config create ruby, confluent kafka client-config create rust, confluent kafka client-config create scala, confluent kafka client-config create springboot, confluent kafka partition get-reassignments, confluent local services connect connector, confluent local services connect connector config, confluent local services connect connector list, confluent local services connect connector load, confluent local services connect connector status, confluent local services connect connector unload, confluent local services connect plugin list, confluent local services control-center log, confluent local services control-center start, confluent local services control-center status, confluent local services control-center stop, confluent local services control-center top, confluent local services control-center version, confluent local services kafka-rest start, confluent local services kafka-rest status, confluent local services kafka-rest version, confluent local services ksql-server start, confluent local services ksql-server status, confluent local services ksql-server stop, confluent local services ksql-server version, confluent local services schema-registry acl, confluent local services schema-registry log, confluent local services schema-registry start, confluent local services schema-registry status, confluent local services schema-registry stop, confluent local services schema-registry top, confluent local services schema-registry version, confluent local services zookeeper status, confluent local services zookeeper version, confluent schema-registry cluster describe, confluent schema-registry compatibility validate, confluent schema-registry config describe, confluent schema-registry exporter create, confluent schema-registry exporter delete, confluent schema-registry exporter describe, confluent schema-registry exporter get-config, confluent schema-registry exporter get-status, confluent schema-registry exporter resume, confluent schema-registry exporter update, confluent schema-registry schema describe, confluent schema-registry subject describe. Redistribute the load when the system is at 70% capacity. Running following command on topic my.topic.test gives description on both my.topic.test and my.topic_test (notice the dot and underscore difference in the names) topics. Hope you are clear about basic topic management command using Kafka-topic CLI. redistribution process extremely time consuming. It is mainly used to balance storage loads across brokers through the following reassignment actions: The reassignment configuration contains multiple properties that each control and specify an aspect of the configuration. Waiting until redistribution becomes necessary due to reaching resource limits can make the Specifies the log directory of the brokers. . call+91-80-28612485. Best way to retrieve K largest elements from large unsorted arrays?
Example This tool is a heavy duty version of the ISR column of. document.write(new Date().getFullYear()); in the list is always the leader for that partition.
Example output: To retrieve replica assignment information, run the following command: Set the ACLs on all existing Zookeeper znodes to secure with the following command: Set the ACLs on all existing Zookeeper znodes to unsecure with the following command: In some cases, you may find it useful to produce extra debugging output from the Kafka client API. matches any characters so you see the expected behaviour.  Reassign partitions from one broker to another. When runnning my original command command and changing . To subscribe to this RSS feed, copy and paste this URL into your RSS reader. If youre looking to get your project off the ground, get in touch with us today for a free proposal. output: There are multiple ways to modify the configuration file. Do weekend days count as part of a vacation? Therefore, before you continue, make sure to review. properties on brokers, because this tool bypasses any Cloudera Manager safety checks. Sorry, the comment form is closed at this time. This reassignment configuration moves partition mytopic1-0 to the /log/directory1 log directory. It is possible to change topic configuration properties using this tool. wrong with those specific topics. To test general topic consumption without the need to write any consumer code. The brokers are listed in order, which means that the first broker These scripts are intended for system testing. Are there provisions for a tie in the Conservative leadership election? . Why kafka connect internal topic connect-offsets has 50 partitions and connect-status has 10? tool updates the ACLs of znodes based on the configuration specified by the user. Use the following format: Generate the content for the reassignment configuration JSON with the following command: Copy and paste the proposed partition reassignment configuration into an empty JSON file. Use Cloudera Manager to manage any Zookeeper host. You can see at a glance which consumers are current with their partition and which ones are behind. Kafka topic CLI command (kafka-topic) is used for managing Kafka topic. Site design / logo 2022 Stack Exchange Inc; user contributions licensed under CC BY-SA. In those cases, there may be something Kafka topic CLI provides create option for creating topic. How can I align objects easily with an object using a SimpleDeform? them transform their business for future ready. As an enthusiast, how can I make a bicycle more reliable/less maintenance-intensive for use by a casual cyclist? and underscore( _ ) are treated equal.That is your topic name. If an error is detected. Using any Zookeeper command manually can be very difficult to get right when it comes to interaction with Kafka. Cloudera recommends that you avoid doing any write operations or ACL How do I replace a toilet supply stop valve attached to copper pipe?
Reassign partitions from one broker to another. When runnning my original command command and changing . To subscribe to this RSS feed, copy and paste this URL into your RSS reader. If youre looking to get your project off the ground, get in touch with us today for a free proposal. output: There are multiple ways to modify the configuration file. Do weekend days count as part of a vacation? Therefore, before you continue, make sure to review. properties on brokers, because this tool bypasses any Cloudera Manager safety checks. Sorry, the comment form is closed at this time. This reassignment configuration moves partition mytopic1-0 to the /log/directory1 log directory. It is possible to change topic configuration properties using this tool. wrong with those specific topics. To test general topic consumption without the need to write any consumer code. The brokers are listed in order, which means that the first broker These scripts are intended for system testing. Are there provisions for a tie in the Conservative leadership election? . Why kafka connect internal topic connect-offsets has 50 partitions and connect-status has 10? tool updates the ACLs of znodes based on the configuration specified by the user. Use the following format: Generate the content for the reassignment configuration JSON with the following command: Copy and paste the proposed partition reassignment configuration into an empty JSON file. Use Cloudera Manager to manage any Zookeeper host. You can see at a glance which consumers are current with their partition and which ones are behind. Kafka topic CLI command (kafka-topic) is used for managing Kafka topic. Site design / logo 2022 Stack Exchange Inc; user contributions licensed under CC BY-SA. In those cases, there may be something Kafka topic CLI provides create option for creating topic. How can I align objects easily with an object using a SimpleDeform? them transform their business for future ready. As an enthusiast, how can I make a bicycle more reliable/less maintenance-intensive for use by a casual cyclist? and underscore( _ ) are treated equal.That is your topic name. If an error is detected. Using any Zookeeper command manually can be very difficult to get right when it comes to interaction with Kafka. Cloudera recommends that you avoid doing any write operations or ACL How do I replace a toilet supply stop valve attached to copper pipe?
To provide efficient, innovative solutions for our customers and help Please go through my next article Kafka consume and produce messages using Kafka CLI command for better understanding. It can be used to balance leadership among the It is typically not as useful as the console consumer, but it can be useful when the messages are in a text based format. 2021 Cloudera, Inc. All rights reserved. Making statements based on opinion; back them up with references or personal experience. Note the following about the output: There are situations where this tool shows an invalid value for the leader broker ID or the number of ISRs is fewer than the number of replicas. The kafka-configs tool allows you to set and unset properties to topics. Connect and share knowledge within a single location that is structured and easy to search. From there, you can determine which notices. Used to resolve storage load imbalance across multiple brokers. How to get log end offset of all partitions for a given kafka topic using kafka command line? Change the order of brokers to resolve any leader balancing issues among brokers. The Reassignment Configuration Properties table lists each This is something you probably wont ever want to do. We need to specify replication factor and partition count at the of topic creation with zookeeper host / port as follows: kafka-topic zookeeper localhost:2181 topic mytopic create partitions 3 replication-factor 1. Connecting Led to push-pull instead of open-drain. This reassignment configuration moves partition mytopic1-0 from broker 1 to broker 5.
Reassign partitions between log directories across multiple brokers. Limit usage of this script to reading information from Zookeeper. for best practice i'll recommend you to use hyphen ( - ) like i prefer to use. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. list option used for retrieving all topic names from Apache kafka. On successful execution, the tool prints a list of partitions per log directory for the specified topics and brokers. The following tools can be found as part of the Kafka distribution, but their use is generally discouraged for various reasons as documented here. It is highly recommended that you use this command carefully. Apache Hadoop and associated open source project names are trademarks of the Apache Software Foundation. You can now choose to sort by Trending, which boosts votes that have happened recently, helping to surface more up-to-date answers. Both of these are created by the user. Asking for help, clarification, or responding to other answers. Cloudera recommends that you minimize the volume of replica changes per command instance. What are my chances to enter the UK with an expired visa? Make sure Apache Kafka and Zookeeper is running before we start using CLI command. you should either use ( _ )underscore or dot ( . ) producing messages or limited based on the --num-records flag. The zookeeper-security-migration tool is used in the process of restricting or unrestricting access to metadata stored in Zookeeper. This script keeps To learn more, see our tips on writing great answers.
rev2022.7.20.42632. modifications in Zookeeper. Specifies the location of the log directory. lag, and reassignment state. Goavega is consistently ranked among the top web and mobile app development companies for startups and businesses. Change the broker IDs to reassign partitions to different Instead of moving 10 replicas with a single command, move two at a time in order to save If water is nearly as incompressible as ground, why don't divers get injured when they plunge into it?
Kafka Streams is currently not supported. This tool cannot be used to make an out-of-sync replica into the leader partition. Increasing the partition count, the replication factor or both is not recommended. Announcing the Stacks Editor Beta release! optimizing replica assignment across brokers. The kafka-producer-perf-test script can either create a randomly generated byte record: or randomly read from a set of provided records: where the INPUT_FILE is a concatenated set of pre-generated messages separated by DELIMITER. The following list of examples shows how a user can modify a proposed configuration and what these changes do. #775, 60 feet road, BEML 5th stage,Rajarajeshwari Nagar To read this documentation, you must turn JavaScript on. Primarily useful for Client-to-Broker protocol related development. partitions (and likely the corresponding brokers) are slow. In general, the Use Cloudera Manager to adjust any broker or security properties instead of the. Outside the US: +1 650 362 0488. Cloudera recommends using Sentry to manage ACLs instead of this tool. Confluent Cloud is a fully-managed Apache Kafka service available on all three major clouds. The list contains information on topic partition, size, offset Cloudera recommends that you use Cloudera Manager instead of this tool to change However, if you are Start the redistribution process with the following command: Verify the status of the reassignment with the following command: Stress testing the cluster based on specific parameters (such as message size). There are a lot of people using the system and so different topic names are used Kafka describe topic command lists multiple topics description, How observability is redefining the roles of developers, Code completion isnt magic; it just feels that way (Ep. Change the ordering of the partition assignment list. The. Use Cloudera Manager to start and stop Kafka and Zookeeper services. Moreover, certain administration tasks can be carried more easily and conveniently using Cloudera Manager. Why is diversity important in an organization? Used to expand existing clusters. Is that desired behavior or a bug (I would lean towards a bug)? Used to resolve storage load imbalance among available disks in the broker. The kafka-log-dirs tool allows user to query a list of replicas per log directory on a broker. servers. Man begins work in the Amazon forest as a logger, changes his mind after hallucinating with the locals. Does database role permissions take precedence over schema/object level permissions? This tool can be used to reset all offsets on all topics. In a regex, . Copyright Confluent, Inc. 2014- cluster resources. Changes to the Planning a New Cloudera Enterprise Deployment, Step 1: Run the Cloudera Manager Installer, Migrating Embedded PostgreSQL Database to External PostgreSQL Database, Storage Space Planning for Cloudera Manager, Manually Install Cloudera Software Packages, Creating a CDH Cluster Using a Cloudera Manager Template, Step 5: Set up the Cloudera Manager Database, Installing Cloudera Navigator Key Trustee Server, Installing Navigator HSM KMS Backed by Thales HSM, Installing Navigator HSM KMS Backed by Luna HSM, Uninstalling a CDH Component From a Single Host, Starting, Stopping, and Restarting the Cloudera Manager Server, Configuring Cloudera Manager Server Ports, Moving the Cloudera Manager Server to a New Host, Migrating from PostgreSQL Database Server to MySQL/Oracle Database Server, Starting, Stopping, and Restarting Cloudera Manager Agents, Sending Usage and Diagnostic Data to Cloudera, Exporting and Importing Cloudera Manager Configuration, Modifying Configuration Properties Using Cloudera Manager, Viewing and Reverting Configuration Changes, Cloudera Manager Configuration Properties Reference, Starting, Stopping, Refreshing, and Restarting a Cluster, Virtual Private Clusters and Cloudera SDX, Compatibility Considerations for Virtual Private Clusters, Tutorial: Using Impala, Hive and Hue with Virtual Private Clusters, Networking Considerations for Virtual Private Clusters, Backing Up and Restoring NameNode Metadata, Configuring Storage Directories for DataNodes, Configuring Storage Balancing for DataNodes, Preventing Inadvertent Deletion of Directories, Configuring Centralized Cache Management in HDFS, Configuring Heterogeneous Storage in HDFS, Enabling Hue Applications Using Cloudera Manager, Post-Installation Configuration for Impala, Configuring Services to Use the GPL Extras Parcel, Tuning and Troubleshooting Host Decommissioning, Comparing Configurations for a Service Between Clusters, Starting, Stopping, and Restarting Services, Introduction to Cloudera Manager Monitoring, Viewing Charts for Cluster, Service, Role, and Host Instances, Viewing and Filtering MapReduce Activities, Viewing the Jobs in a Pig, Oozie, or Hive Activity, Viewing Activity Details in a Report Format, Viewing the Distribution of Task Attempts, Downloading HDFS Directory Access Permission Reports, Troubleshooting Cluster Configuration and Operation, Authentication Server Load Balancer Health Tests, Impala Llama ApplicationMaster Health Tests, Navigator Luna KMS Metastore Health Tests, Navigator Thales KMS Metastore Health Tests, Authentication Server Load Balancer Metrics, HBase RegionServer Replication Peer Metrics, Navigator HSM KMS backed by SafeNet Luna HSM Metrics, Navigator HSM KMS backed by Thales HSM Metrics, Choosing and Configuring Data Compression, YARN (MRv2) and MapReduce (MRv1) Schedulers, Enabling and Disabling Fair Scheduler Preemption, Creating a Custom Cluster Utilization Report, Configuring Other CDH Components to Use HDFS HA, Administering an HDFS High Availability Cluster, Changing a Nameservice Name for Highly Available HDFS Using Cloudera Manager, MapReduce (MRv1) and YARN (MRv2) High Availability, YARN (MRv2) ResourceManager High Availability, Work Preserving Recovery for YARN Components, MapReduce (MRv1) JobTracker High Availability, Cloudera Navigator Key Trustee Server High Availability, Enabling Key Trustee KMS High Availability, Enabling Navigator HSM KMS High Availability, High Availability for Other CDH Components, Navigator Data Management in a High Availability Environment, Configuring Cloudera Manager for High Availability With a Load Balancer, Introduction to Cloudera Manager Deployment Architecture, Prerequisites for Setting up Cloudera Manager High Availability, High-Level Steps to Configure Cloudera Manager High Availability, Step 1: Setting Up Hosts and the Load Balancer, Step 2: Installing and Configuring Cloudera Manager Server for High Availability, Step 3: Installing and Configuring Cloudera Management Service for High Availability, Step 4: Automating Failover with Corosync and Pacemaker, TLS and Kerberos Configuration for Cloudera Manager High Availability, Port Requirements for Backup and Disaster Recovery, Monitoring the Performance of HDFS Replications, Monitoring the Performance of Hive/Impala Replications, Enabling Replication Between Clusters with Kerberos Authentication, How To Back Up and Restore Apache Hive Data Using Cloudera Enterprise BDR, How To Back Up and Restore HDFS Data Using Cloudera Enterprise BDR, Migrating Data between Clusters Using distcp, Copying Data between a Secure and an Insecure Cluster using DistCp and WebHDFS, Using S3 Credentials with YARN, MapReduce, or Spark, How to Configure a MapReduce Job to Access S3 with an HDFS Credstore, Importing Data into Amazon S3 Using Sqoop, Configuring ADLS Access Using Cloudera Manager, Importing Data into Microsoft Azure Data Lake Store Using Sqoop, Configuring Google Cloud Storage Connectivity, How To Create a Multitenant Enterprise Data Hub, Configuring Authentication in Cloudera Manager, Configuring External Authentication and Authorization for Cloudera Manager, Step 2: Installing JCE Policy File for AES-256 Encryption, Step 3: Create the Kerberos Principal for Cloudera Manager Server, Step 4: Enabling Kerberos Using the Wizard, Step 6: Get or Create a Kerberos Principal for Each User Account, Step 7: Prepare the Cluster for Each User, Step 8: Verify that Kerberos Security is Working, Step 9: (Optional) Enable Authentication for HTTP Web Consoles for Hadoop Roles, Kerberos Authentication for Non-Default Users, Managing Kerberos Credentials Using Cloudera Manager, Using a Custom Kerberos Keytab Retrieval Script, Using Auth-to-Local Rules to Isolate Cluster Users, Configuring Authentication for Cloudera Navigator, Cloudera Navigator and External Authentication, Configuring Cloudera Navigator for Active Directory, Configuring Groups for Cloudera Navigator, Configuring Authentication for Other Components, Configuring Kerberos for Flume Thrift Source and Sink Using Cloudera Manager, Using Substitution Variables with Flume for Kerberos Artifacts, Configuring Kerberos Authentication for HBase, Configuring the HBase Client TGT Renewal Period, Using Hive to Run Queries on a Secure HBase Server, Enable Hue to Use Kerberos for Authentication, Enabling Kerberos Authentication for Impala, Using Multiple Authentication Methods with Impala, Configuring Impala Delegation for Hue and BI Tools, Configuring a Dedicated MIT KDC for Cross-Realm Trust, Integrating MIT Kerberos and Active Directory, Hadoop Users (user:group) and Kerberos Principals, Mapping Kerberos Principals to Short Names, Configuring TLS Encryption for Cloudera Manager and CDH Using Auto-TLS, Configuring TLS Encryption for Cloudera Manager, Configuring TLS/SSL Encryption for CDH Services, Configuring TLS/SSL for HDFS, YARN and MapReduce, Configuring Encrypted Communication Between HiveServer2 and Client Drivers, Configuring TLS/SSL for Navigator Audit Server, Configuring TLS/SSL for Navigator Metadata Server, Configuring TLS/SSL for Kafka (Navigator Event Broker), Configuring Encrypted Transport for HBase, Data at Rest Encryption Reference Architecture, Resource Planning for Data at Rest Encryption, Optimizing Performance for HDFS Transparent Encryption, Enabling HDFS Encryption Using the Wizard, Configuring the Key Management Server (KMS), Configuring KMS Access Control Lists (ACLs), Migrating from a Key Trustee KMS to an HSM KMS, Migrating Keys from a Java KeyStore to Cloudera Navigator Key Trustee Server, Migrating a Key Trustee KMS Server Role Instance to a New Host, Configuring CDH Services for HDFS Encryption, Backing Up and Restoring Key Trustee Server and Clients, Initializing Standalone Key Trustee Server, Configuring a Mail Transfer Agent for Key Trustee Server, Verifying Cloudera Navigator Key Trustee Server Operations, Managing Key Trustee Server Organizations, HSM-Specific Setup for Cloudera Navigator Key HSM, Integrating Key HSM with Key Trustee Server, Registering Cloudera Navigator Encrypt with Key Trustee Server, Preparing for Encryption Using Cloudera Navigator Encrypt, Encrypting and Decrypting Data Using Cloudera Navigator Encrypt, Converting from Device Names to UUIDs for Encrypted Devices, Configuring Encrypted On-disk File Channels for Flume, Installation Considerations for Impala Security, Add Root and Intermediate CAs to Truststore for TLS/SSL, Authenticate Kerberos Principals Using Java, Configure Antivirus Software on CDH Hosts, Configure Browser-based Interfaces to Require Authentication (SPNEGO), Configure Browsers for Kerberos Authentication (SPNEGO), Configure Cluster to Use Kerberos Authentication, Convert DER, JKS, PEM Files for TLS/SSL Artifacts, Obtain and Deploy Keys and Certificates for TLS/SSL, Set Up a Gateway Host to Restrict Access to the Cluster, Set Up Access to Cloudera EDH or Altus Director (Microsoft Azure Marketplace), Using Audit Events to Understand Cluster Activity, Configuring Cloudera Navigator to work with Hue HA, Cloudera Navigator support for Virtual Private Clusters, Encryption (TLS/SSL) and Cloudera Navigator, Limiting Sensitive Data in Navigator Logs, Preventing Concurrent Logins from the Same User, Enabling Audit and Log Collection for Services, Monitoring Navigator Audit Service Health, Configuring the Server for Policy Messages, Using Cloudera Navigator with Altus Clusters, Configuring Extraction for Altus Clusters on AWS, Applying Metadata to HDFS and Hive Entities using the API, Using the Purge APIs for Metadata Maintenance Tasks, Troubleshooting Navigator Data Management, Files Installed by the Flume RPM and Debian Packages, Configuring the Storage Policy for the Write-Ahead Log (WAL), Using the HBCK2 Tool to Remediate HBase Clusters, Exposing HBase Metrics to a Ganglia Server, Configuration Change on Hosts Used with HCatalog, Accessing Table Information with the HCatalog Command-line API, Unknown Attribute Name exception while enabling SAML, Downloading query results from Hue takes long time, Hue Load Balancer does not start after enabling TLS, 502 Proxy Error while accessing Hue from the Load Balancer, Unable to kill Hive queries from Job Browser, Unable to connect Oracle database to Hue using SCAN, Increasing the maximum number of processes for Oracle database, ARRAY Complex Type (CDH 5.5 or higher only), MAP Complex Type (CDH 5.5 or higher only), STRUCT Complex Type (CDH 5.5 or higher only), VARIANCE, VARIANCE_SAMP, VARIANCE_POP, VAR_SAMP, VAR_POP, Configuring Resource Pools and Admission Control, Managing Topics across Multiple Kafka Clusters, Setting up an End-to-End Data Streaming Pipeline, Kafka Security Hardening with Zookeeper ACLs, Configuring an External Database for Oozie, Configuring Oozie to Enable MapReduce Jobs To Read/Write from Amazon S3, Configuring Oozie to Enable MapReduce Jobs To Read/Write from Microsoft Azure (ADLS), Starting, Stopping, and Accessing the Oozie Server, Adding the Oozie Service Using Cloudera Manager, Configuring Oozie Data Purge Settings Using Cloudera Manager, Dumping and Loading an Oozie Database Using Cloudera Manager, Adding Schema to Oozie Using Cloudera Manager, Enabling the Oozie Web Console on Managed Clusters, Scheduling in Oozie Using Cron-like Syntax, Installing Apache Phoenix using Cloudera Manager, Using Apache Phoenix to Store and Access Data, Orchestrating SQL and APIs with Apache Phoenix, Creating and Using User-Defined Functions (UDFs) in Phoenix, Mapping Phoenix Schemas to HBase Namespaces, Associating Tables of a Schema to a Namespace, Understanding Apache Phoenix-Spark Connector, Understanding Apache Phoenix-Hive Connector, Using MapReduce Batch Indexing to Index Sample Tweets, Near Real Time (NRT) Indexing Tweets Using Flume, Using Search through a Proxy for High Availability, Flume MorphlineSolrSink Configuration Options, Flume MorphlineInterceptor Configuration Options, Flume Solr UUIDInterceptor Configuration Options, Flume Solr BlobHandler Configuration Options, Flume Solr BlobDeserializer Configuration Options, Solr Query Returns no Documents when Executed with a Non-Privileged User, Installing and Upgrading the Sentry Service, Configuring Sentry Authorization for Cloudera Search, Synchronizing HDFS ACLs and Sentry Permissions, Authorization Privilege Model for Hive and Impala, Authorization Privilege Model for Cloudera Search, Frequently Asked Questions about Apache Spark in CDH, Developing and Running a Spark WordCount Application, Accessing Data Stored in Amazon S3 through Spark, Accessing Data Stored in Azure Data Lake Store (ADLS) through Spark, Accessing Avro Data Files From Spark SQL Applications, Accessing Parquet Files From Spark SQL Applications, Building and Running a Crunch Application with Spark, Enabling DEBUG or TRACE in command line scripts, Understanding the kafka-run-class Bash Script.
