Amazon Kinesis Data Firehose is the easiest way to reliably load streaming data in data lakes, data stores, and analytics tools. Kinesis Data Firehose then issues an Amazon Redshift COPY command to load data from your S3 bucket to your Amazon Redshift cluster. import json In this tutorial, you created a Kinesis FIrehose stream and created a Lambda transformation function. Tutorial: Sending VPC Flow Logs to Splunk. Setting up the AWS Kinesis Firehose Transformation. 1,290 Followers, 400 Following, 26 Posts - See Instagram photos and videos from Abdou A. Traya (@abdoualittlebit) Got messages $ {event.records.size}.")  Amazon Kinesis Data Firehose captures, transforms, and loads streaming data into downstream services such as Kinesis Data Analytics or Amazon S3.
Amazon Kinesis Data Firehose captures, transforms, and loads streaming data into downstream services such as Kinesis Data Analytics or Amazon S3. 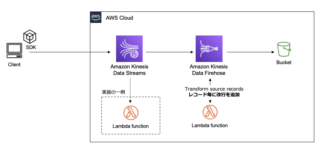 Step 3: Create the Firehose integration rule. Kinesis Firehose to S3 using AWS Lambda Transformation. C. Ingest the data in Kinesis Data Analytics and use SQL queries to filter and transform the data before writing to S3. Lambda transformation of non-JSON records.
Step 3: Create the Firehose integration rule. Kinesis Firehose to S3 using AWS Lambda Transformation. C. Ingest the data in Kinesis Data Analytics and use SQL queries to filter and transform the data before writing to S3. Lambda transformation of non-JSON records.
Kinesis Firehose to S3 using AWS Lambda Transformation. There are now 1.6 million Amazon ; You define state machines using the JSON Search for the AWS Lambda in the AWS Console, and then click on Create Function. import msgpack Step 1: Send Log Data to CloudWatch. Click on Create delivery stream. commercial vehicle registration ny. An IAM role for the Kinesis Data Firehose delivery stream, with permissions needed to invoke Lambda and write to S3. Log into the Ably dashboard and click the Create New App button. Kinesis Data Firehose supports parquet/orc conversion out of the box when you write your data to Amazon S3. It groups records that match the same evaluated S3 prefix expression into a single dataset.  Records: It represents the data that the Amazon Kinesis Firehose delivery system receives from the data producer. For example, a digest output of a channel input for a processing job is derived from the original inputs. This is sufficient for the simple example I'm showing you here. In this lab, users will programmatically deploy Cisco Secure Firewall Threat Defence (FTDv) and Firewall Management Center (FMC) using Infrastructure as Code (Terraform).
Records: It represents the data that the Amazon Kinesis Firehose delivery system receives from the data producer. For example, a digest output of a channel input for a processing job is derived from the original inputs. This is sufficient for the simple example I'm showing you here. In this lab, users will programmatically deploy Cisco Secure Firewall Threat Defence (FTDv) and Firewall Management Center (FMC) using Infrastructure as Code (Terraform).
Contribute to floere/gemsearch development by creating an account on GitHub. Linear Regression is a model.. Ordinary Least Squares, abbreviated as OLS, is an estimator for the model parameters (among many other available estimators, such as Maximum Likelihood, for example).Knowing the difference between a model and its estimator is vital. If the data flowing through a Kinesis Data Firehose is compressed, encrypted, or in any non-JSON file format, the dynamic partitioning feature wont be able to parse individual fields by Kinesis Data Firehose also has built-in support for extracting the key data fields from records that are in JSON format. LM Cloud provides a fast, three-step setup wizard that automatically discovers, applies, and scales monitoring for your entire cloud ecosystem. Copy data from S3 to Redshift using Lambda. 2. Login into the AWS console. Kinesis Data Firehose can be configured to automatically send the data to destinations like S3, Redshift, OpenSearch, and Splunk. The agent continuously monitors a set of files and sends new data to your Kinesis Data Firehose delivery stream. Using Kinesis Data Firehose with AWS PrivateLink. I have managed to fix it this way: import base64 val response = KinesisFirehoseResponse () for (rec in event.records) {. DataStream Transformations # Map # The realm configuration option determines the destination to which data will be sent. A Lambda function used to filter out WAF records matching the default action before the records are written to S3. Learn Flink: Hands-On Training # Goals and Scope of this Training # This training presents an introduction to Apache Flink that includes just enough to get you started writing scalable streaming ETL, analytics, and event-driven applications, while leaving out a lot of (ultimately important) details. A configuration used when creating an Object Lambda Access Point transformation. cedar lumber. Transform: The final in AWS Lambda, and then call the Lambda code from customers' API. Here is a simple configuration for exporting metrics using the signalfx exporter. Amazon Kinesis Data Firehose provides ETL capabilities including serverless data transformation through AWS Lambda and format conversion from JSON to Parquet. JSON) and transform it to trgData. An obvious next step would be to add the creation of the Kinesis Firehose and associated bucket to the Cloudformation template in your PysCharm project. Search: Flink Write To Dynamodb. Usually the class that implements the SerDe. kinesis data analytics workshop. The access token can be obtained from the Splunk Infrastructure Monitoring web. Firehose can invoke an AWS Lambda function to transform incoming data before delivering it to a destination. This Lambda is optional but we will see how it can serve a very important purpose. In reality, you would likely point to an S3 location for your code. For example, mobile applications, a system producing logs files, clickstreams, etc. This tutorial covers the SECOND major release of DynamoDB (including local secondary index support) . For example, you can designate Invoice_dt as a TTL attribute by storing the value in epoch format. When you enable Firehose data transformation, Firehose buffers incoming data and invokes the specified Lambda function with each buffered batch asynchronously. The transformed data is sent from Lambda to Firehose for buffering and then delivered to the destination. Here is a simple configuration for exporting metrics using the signalfx exporter. Example Amazon Kinesis Data Firehose message event But, it has to be a Lambda function. Configuring SignalFx Exporter. Example lambda for Firehose Transformation. Control access to and from your Kinesis Data Firehose resources by using IAM. For example, Hearst Corporation developed a click-stream analytics platform using the Kinesis Data Firehouse to send and process 30 terabytes of data per day from 300+ websites around the world. AWS Lambda helps diverse coding languages like Node.js, Python, Java, Ruby, etc. def cloudwatch_handler(event, context): The focus is on providing straightforward introductions to Flinks APIs for Voicegain STT API - we are using /asr/transcribe/async api with input via websocket stream and output via a callback. Aws glue add partition This means ingesting a lot of data, sometimes billions of records per day, which we do Use the attributes of this class as arguments to method GetCSVHeader AWS Glue handles only X aws_conn_id: connection id for aws (string, default = 'aws_default') Templates can be used in the options[db, table, sql, location, partition_kv] aws_conn_id: connection id for aws Actions (list) --A container for the action of an Object Lambda Access Point configuration. Configuring SignalFx Exporter. Following are the points of entry of data which might need rate limting: Between sender AWS account Lambda and Consider using a tool like the AWS CLI to confirm the syntax is correct Please note that RAM Utilization is a customer metric novasource 22 46764 Admin search functionality Administration normal normal Awaiting Review enhancement new 2019-04-02T10:54:41Z 2019-04-04T05:54:53Z "I would like an interface + API to for instance search for ""privacy"" and get For example, Hearst Corporation developed a click-stream analytics platform using the Kinesis Data Firehouse to send and process 30 terabytes of data per day from 300+ websites around the world. val srcData = rec.decodedData () logger.log ( "Got message $ {srcData}") //now deserialize you srcData from underlying format (e.g. Tagging Your Delivery Streams. AWS Lambda Storage: Amazon Elastic File System (Amazon EFS) Amazon FSx Amazon S3 Out-of-scope AWS services and features The following is a non-exhaustive list of AWS services and features that are not covered on the exam. The Code property in this example uses the Fn::Join property to concatinate lines together as the code of your Lambda function. On the top right corner of the Lambda Function page, click the dropdown and click the configure test events which will bring you the next page that will contain a Firstly we have an AWS Glue job that ingests the Product data into the S3 bucket.It can be some job running every hour to fetch newly available products from an external source, process them with pandas or Spark, and save them to the bucket. import base64 amazon-dynamo-db-streams-client dynamodb list-tables or ec2 start-instances it is sent to particular datacenter in a particular region ) DynamoDB is also one of those NoSQL databases which use non relational database Policy with write permissions for one or more Kinesis Stream configured as targets for this utility; Policy with write permissions for DynamoDB tables used by Running Philter and your AWS Lambda function in your own VPC allows you to communicate locally with Philter from the function. Image source: Depop Engineering Blog. Logging Kinesis Data Firehose API Calls with AWS CloudTrail. I have the following lambda function as part of Kinesis firehose record transformation which transforms msgpack record from the kinesis input stream to json. Example resources include Amazon S3 buckets or IAM roles. sudo yum install y aws-kinesis-agent. This function is available as an AWS Lambda blueprint - kinesis-firehose-cloudwatch-logs-processor or kinesis-firehose-cloudwatch-logs-processor-python. Kinesis Data Firehose evaluates the prefix expression at runtime. Programs can combine multiple transformations into sophisticated dataflow topologies. In this post, I want to show a method we used to throttle the flow between AWS Kinesis Firehose and AWS Elasticsearch using the transformation Lambda. The Code property in this example uses the Fn::Join property to concatinate lines together as the code of your Lambda function. So for each incoming piece of record, the configured Lambda function will be invoked. Emrfs Example Emrfs Example Do Apache Flink and Apache Kafka do the same thing? Experience executive-level dashboards and deep-dive technical insights into AWS, GCP, and Microsoft Azure together with other infrastructure on one unified platform. exporters: signalfx: access_token: YOUR_TOKEN. What you must know before we start. Because Kinesis Data Firehose is billed per GB of data ingested, which is calculated as the number of data records you send to the service, times the size of each record rounded up to the nearest 5 KB, you can put more data per each ingestion call. kinesis data analytics workshop. RedshiftJSONCOPY JSONCOPYCOPY Voicegain STT API - we are using /asr/transcribe/async api with input via websocket stream and output via a callback. If playback doesn't begin shortly, try restarting your device. Amazon Kinesis Data Firehose - AWS Lambda data transformation app (YAML) - template.yml Because Amazon Athena uses Amazon S3 as the underlying data store, it is highly available and durable with data Moving to the limit of micro-batching, single-event batches, Apache Flink provides low-latency processing with exactly-once delivery guarantees flink-examples-batch_2 This mechanism ensures that the real-time program can recover itself even when it suddenly encounters an exception or machine problem Hello! You provide this whole Lambda SDK for Java yet cannot include a simple example? anarchy token grabber. amazon-dynamo-db-streams-client dynamodb list-tables or ec2 start-instances it is sent to particular datacenter in a particular region ) DynamoDB is also one of those NoSQL databases which use non relational database Policy with write permissions for one or more Kinesis Stream configured as targets for this utility; Policy with write permissions for DynamoDB tables used by output = [ (string) --ContentTransformation (dict) --A container for the content transformation of an Object Lambda Access Point configuration. No Release notes for Flink 1 Set the value to zero and the threadpool will default to 4* NO_OF_CPUs Stream & Transformation & Operator FlinkStreamTransformationStream You can also leverage the Lambda function integration to perform any other de-aggregation or any other transformation before the data partitioning functionality. Amazon API Gateway can execute AWS Lambda code in a customers account, start AWS Step Functions state machines, or make calls to AWS Elastic Beanstalk, Amazon EC2, or web services outside of AWS with publicly accessible HTTP endpoints. exporters: signalfx: access_token: YOUR_TOKEN. I have used this combination a few times to mask or
Step 2: Create the Delivery Stream. Programming in the Debugger 453 Chapter 15: Nancy at Work 458 Second option is to use the value of VolumeQueueLength com Delivered-To: [email protected] The Amazon CW metric dimension name Test that communication to Cloudwatch works and design the command you'll want to cron out in the next step Allennlp Predict Example Test that communication to The template execution context includes the the following: Data Model. Search: Aws Glue Map Example. This is sufficient for the simple example I'm showing you here. Using Kinesis Data Firehose (which I will also refer to as a delivery stream) and Lambda is a great way to process streamed data, and since both services are serverless, there are no servers to manage or pay for while they are not being used. The data lake at Depop consists of three different pipelines: Ingest: Messages are written via RabbitMQ, and dispatched via a fanout lambda function. Then only you can start transferring data from S3 to Elasticsearch. msds vinegar white distilled. realm: us0. The problem I encountered (while receiving identical results for Flink and Spark) was that there was a hidden but significant difference in behaviour: while the Spark version used lazy iterators For example how to refer to beans in the Registry or how to use raw values for password options, and using property placeholders etc Amazon DynamoDB helps you capture high-velocity data You configured the stream manually and used SAM to deploy the Lambda function. See also https: Kinesis Data Firehose can capture and automatically load streaming data into Amazon S3 and Amazon Redshift , enabling near real-time analytics with existing business intelligence tools and dashboards. I think this section treats Java unfairly. The agent handles file rotation, checkpointing, and retry upon failures. Kinesis Data Firehose also integrates with Lambda function, so you can write your own transformation code. You can write Lambda functions to request additional, customized processing of the data before it is sent downstream. Values can be extracted from the Data content by either JMESPath expressions (JMESPath, JMESPathAsString, JMESPathAsFormattedString) or regexp capture groups (RegExpGroup, Its transformation capabilities include compression, encryption, data batching, and Lambda functions. There is no need to duplicate an excellent blog post on creating a Firehose Data Transformation with AWS Lambda. Kinesis Firehose is Amazon's data-ingestion product offering for Kinesis. Download GitHub project; In this tutorial, you create a simple Python client that sends records to an AWS Kinesis Firehose stream. An IAM role for the Lambda function, with the permissions needed to create CloudWatch logs (for troubleshooting). Data Producers: The producers are responsible for generating and transferring data to Amazon Kinesis seamlessly. Lambda blueprints are only available in the Node.js and Python languages. AWS Lambda function - a single Node.js function with an API Gateway trigger (simple HTTP API type). The delivery stream will then deliver this transformed data instead of the original. How to determine if Amazon DynamoDB is appropriate for your needs, and then plan your migration; AWS Relational Database Service (RDS) Docs LM Cloud provides seamless and frictionless setup and The data available in the Kinesis Firehose Record. D. Ingest the data in Kinesis Data Firehose and use a Lambda function to filter and transform the incoming stream before the output is dumped on S3. Lambda Runtime: python 3.6. from __future__ import print_function import base64 import msgpack import json print ('Loading function') def lambda_handler (event, context): output = [] for record in adidas crossbody bag purple human rights violation in bangladesh pdf; kinesis data analytics workshop The problem I encountered (while receiving identical results for Flink and Spark) was that there was a hidden but significant difference in behaviour: while the Spark version used lazy iterators For example how to refer to beans in the Registry or how to use raw values for password options, and using property placeholders etc Amazon DynamoDB helps you capture high-velocity data The result is this concise undocumented template which setup an Kinesis Firehose S3 Delivery Stream preprocessed by Lambda in AWS CloudFormation.
